
Shuffle阶段涉及序列化反序列化、跨节点网络IO以及磁盘读写IO等,代价很高。
shuffle write:每个map task将计算结果分成多份,每一份对应到下游stage的每个partition中,并且临时写到磁盘。
shuffle read:reduce task通过网络拉取map task的指定分区结果数据。
Spark Shuffle 实现演进
Hash Shuffle
1.1版本以前实现方式,2.0版本已淘汰
更早版本的Hash Shuffle 每个map task都会为每个partition写一个文件。假设有n个partition,一个executor上有m个map task,那么就会有n*m个文件。生成文件时需要申请文件描述符,当partition很多时,并行化运行task时可能会耗尽文件描述符、消耗大量内存。因此后来Hash Shuffle进一步变成了如下版本。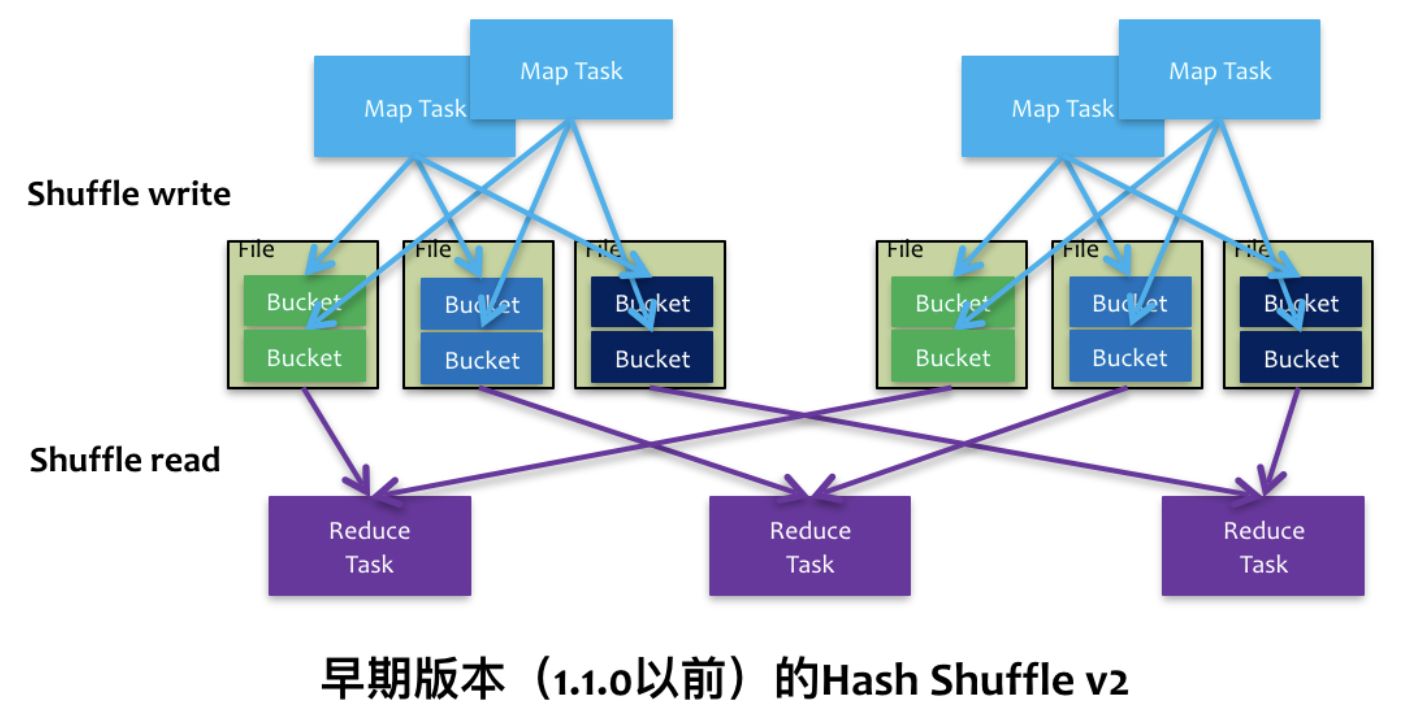
为了减少临时文件数,一个core上所有map task的相同分区的文件会进行合并,这样最多只有n个文件。但是当partition个数很多时还是没解决问题,容易OOM。
Sort Shuffle
借鉴了Hadoop Shuffle的处理方式,对中间结果进行了排序。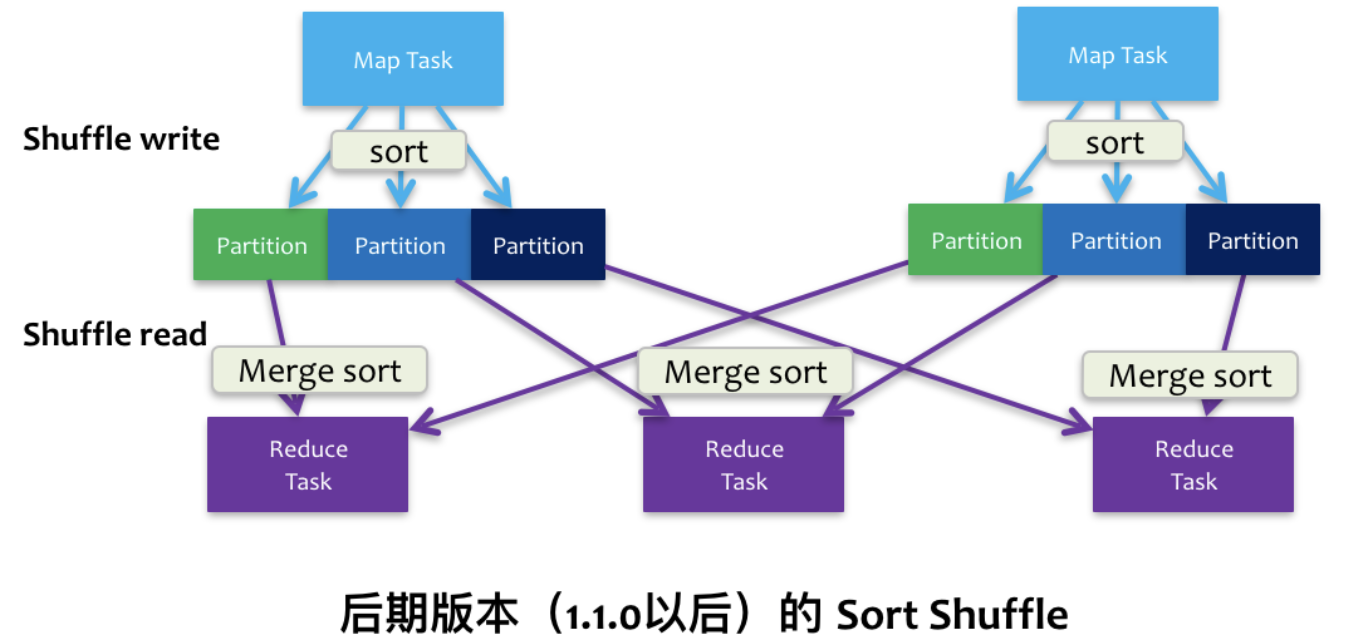
- 在map阶段,会先按照partition id、每个partition内部按照key对中间结果进行排序。所有的partition数据写在一个文件里,并且通过一个索引文件记录每个partition的大小和偏移量。这样并行运行时每个core只要2个文件,一个executor上最多2m个文件。。
- 在reduce阶段,reduce task拉取数据做combine时不再使用
HashMap而是ExternalAppendOnlyMap。如果内存不足会写次磁盘。
排序会导致性能损失。
Unsafe Shuffle (Tungsten-sort)
为了进一步的优化内存和CPU使用,提升spark性能,引入了Unsafe Shuffle。设计了一套新的内存管理机制,类似操作系统的page table结构对内存进行管理。将中间结果以二进制的方式存储到堆外内存,直接在序列化的二进制数据上排序而不是java对象。排序的不是内容本身,而是内容序列化后字节数组的指针(元数据),把数据的排序转变为了指针数组的排序,实现了直接对序列化后的二进制数据进行排序。既减少了内存使用和GC开销,也避免了频繁的序列化很反序列化。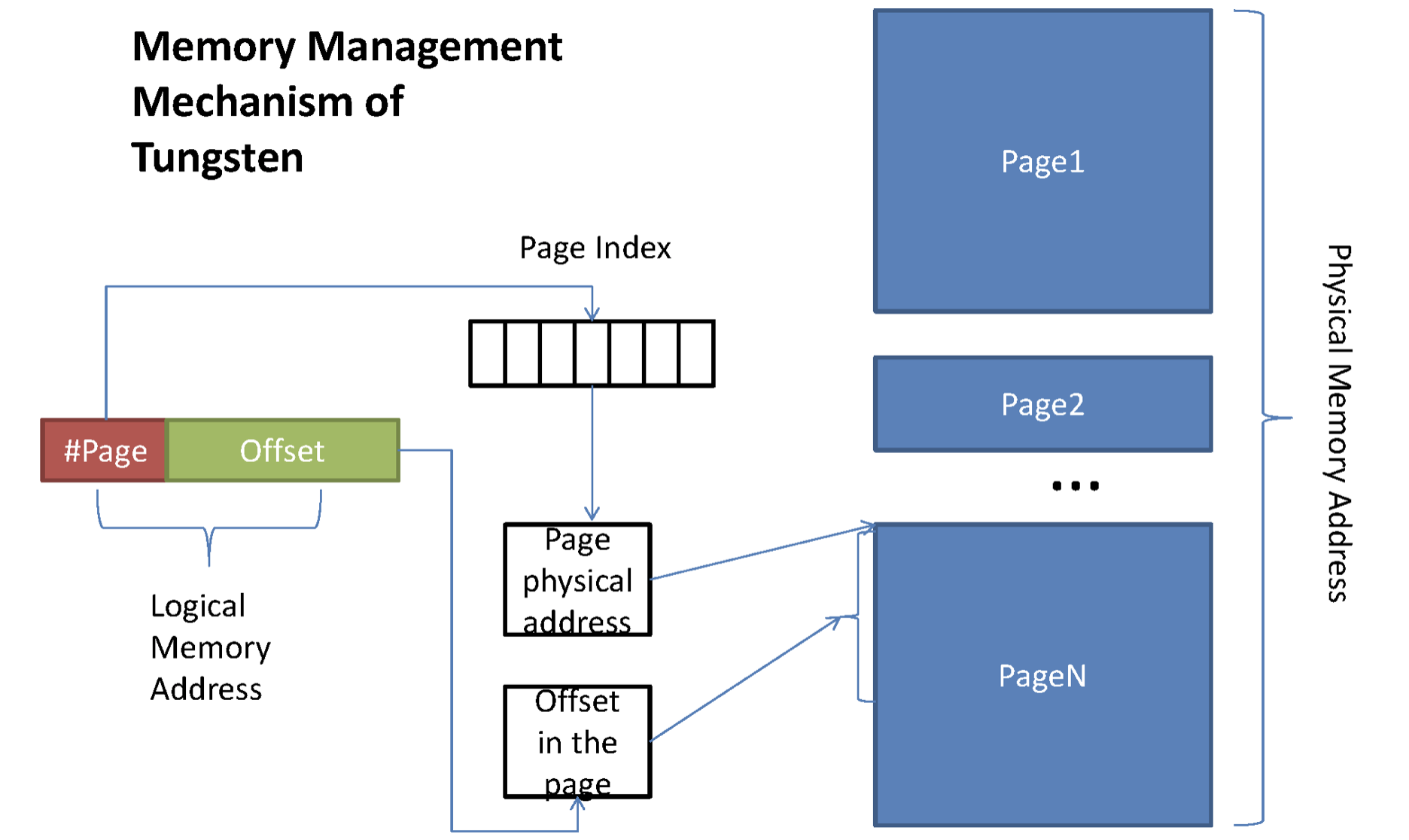
Unsafe Shuffle使用了堆外内存,支持off-heap和in-heap模式- 在off-heap模式,内存通过一个64bits的绝对内存地址表示。obj为null,offset则为绝对的内存地址
- 在in-heap模式,内存由相对于一个JVM对象的偏移表示。obj则是JVM对象的基地址,offset则是相对于改对象基地址的偏移
- #page为13bit,Offset为51bit
- Offset == 24bit分区号 + 13bit page号 + 27bit page内偏移量,$2^{13} * 128M = 1TB$
- 24bit分区号就是为了进行分区排序,key没别编码进去因此不能排序
- 整个过程没有反序列化
- 其他部分和SortShuffle没有什么区别,步骤都是类似的
限制:shuffle阶段不能有aggregate操作;输出不能需要排序;分区数不超过$2^{24} - 1$;序列化后单条记录不能超过128M(一个page的大小);序列化器需要是KryoSerializer等
Sort Shuffle包括Unsafe Shuffle,当条件符合就优先使用Unsafe Shuffle。
ByPassMergeSort Shuffle
借鉴了Hash Shuffle的思想,对于分区少于200(参数spark.shuffle.sort.bypassMergeThreshold默认设置)且不需要聚合排序的算子,优先使用这种策略。但是和Hash Shuffle不一样的是,一个maptask虽然会为每个partition生成一个文件,但是在task最终还是会把它们合并成一个数据文件+一个索引文件。
优势:避免了排序
Shuffle详细实现流程
针对SortShuffle的实现,具体解释整个实现流程。
Shuffle Write
Shuffle Write 主要分为三个阶段:
- map的输出结果会写入
PartitionedAppendOnlyMap相当于一个缓冲区,当这部分的内存写满了就会往磁盘溢写。 - 溢写称之为spill操作。在往磁盘溢写之前,会对数据进行排序,然后溢写。每个临时文件spill都会被记录在一个数组里
- 当一个map task执行完毕之后,对所有的临时文件和内存中的结果进行merge操作,做归并排序,然后输出最终结果并且生成索引文件。
关于磁盘溢写:
如果当前使用内存超过5M(spark.shuffle.spill.initalMemoryThreshold设置大小,默认5M,主要是防止spill的文件过小),map task会向shuffleMemoryManager申请2 * currentMemory - myMemoryThreshold大小的内存,如果申请不到就会触发spill操作。shuffleMemoryManager是executor上所有task共享的, 并行task共享executor的内存,executor能分配出去的内存是executorHeapMemory * spark.shuffle.memoryFraction * spark.shuffle.safetyFraction。由于内存检查estimateSize是使用采样算法来进行估算的,采样周期不固定,呈指数增长。因此内存开的越大反而容易OOM,可以适当调低spark.shuffle.safetyFraction参数。
因此spark内存使用是很激进的,如果中间结果内存放得下会放进内存,在task最后将中间结果写入磁盘。
Shuffle Read
Reference
Spark Shuffle的演变,Spark Shuffle原理及相关调优
Spark Shuffle的技术演进
Spark Tungsten-sort Based Shuffle 分析
探索Spark Tungsten的秘密