
MiniHippo
人生三件快事:吃,睡,打代码
combineByKey, reduceByKey, aggregatedByKey等区别
reduceByKey,aggregatedByKey都是基于combineByKey。groupByKey没有mapside combine。
Spark MLlib Word2Vec 原理
基于Spark的word2vec采用的是基于Hierarchical Softmax的Skip-gram模型
Skip-gram 模型
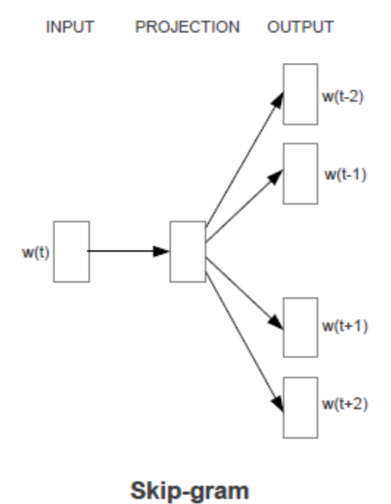
结构:输入层+隐藏层+输出层
输入:某个词的词向量
输出:该词对应的上下文,若上下文的窗口为5,那么输出就是softmax概率排名前10的词。
Spark job, stage,task划分与提交
进入8080端口看到Spark任务管理也页面,可以看到我们提交的任务是有一个Application ID。点进去会分成多个Job ID,点进一个job又有多个stage,stage点进去就是executor和task的详细情况。
显然,Application > Job > Stage > Task。
Spark Shuffle 原理
Shuffle阶段涉及序列化反序列化、跨节点网络IO以及磁盘读写IO等,代价很高。
shuffle write:每个map task将计算结果分成多份,每一份对应到下游stage的每个partition中,并且临时写到磁盘。
shuffle read:reduce task通过网络拉取map task的指定分区结果数据。
缺失模块。
1、请确保node版本大于6.2
2、在博客根目录(注意不是yilia根目录)执行以下命令:
npm i hexo-generator-json-content --save
3、在根目录_config.yml里添加配置:
jsonContent:
meta: false
pages: false
posts:
title: true
date: true
path: true
text: false
raw: false
content: false
slug: false
updated: false
comments: false
link: false
permalink: false
excerpt: false
categories: false
tags: true